This is nr. 3 of some blog posts on Parallel Stream Compaction. In previous posts we saw that the implementation by Billeter et al. is a factor faster than implementations by Orange Owls and Spataro, and that a multiplicative relation exists, even when using different graphics cards. We wondered if the essential difference between the implementations is that the former uses loops that process the input in subsequences, and the latters do not.
In this post we will examine loops and sequences in a Cuda copy program, a simpler context than stream compaction. The program takes a long array and returns a copy. Simple as that. The question here is if the use of loops can account for the difference in performance mentioned above, and if so, can we say something about optimal parameter configurations.
This investigation compares loops and subsequences set up according to Billeter et al. to not using loops at all, “grid stride loops” as advocated by Nvidia [1], and warp stride loops which is a generalization of the way Billeter et al. organize loops. For the latter three algorithms we will do a parameter search to (by and large) optimize parameter settings. Recall that the former algorithm has fixed parameters for the number of threads per thread-block and the number of blocks
A link to sample code can be found at the bottom of this post. (not yet, but on its way!)
No loops, Grid stride loops, Billeter et al. loops, and Warp stride loops
The task will be to copy an array of 2^24 elements. The elements are chosen using c++ rand();
No loops
If we do not use loops or sequences we can copy the array with a function like the one below. It is a template, so we can easily experiment with different types of arguments.
template
__global__ void device_copy_kernel1(T* d_in, T* d_out)
{
// Determine global index into the arrays
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// Copy the element
d_out[idx] = d_in[idx];
}
I used arrays of unsigned int in the experiments described here.
Grid stride loops
When using grid stride loops, the step size equals the entire grid of threads. The size of a grid is
number-of-threads-per-block x number-of-blocks
i.e., the entire number of threads used by the program. We can choose the total number of threads freely, but if we also choose wisely, it is a divisor of the array size, and we choose the block size to be a multiple of the warp size: 32 for current hardware. The maximum block size is 1024.
A simple function to copy an array using grid stride loops is the following.
template
__global__ void device_copy_kernel2(T* d_in, T* d_out)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < ARRAY_SIZE; i += blockDim.x * gridDim.x)
{
d_out[i] = d_in[i];
}
}
Billeter et al. loops, Warp stride loops
Billeter et al. have set the number of threads per block to 128, and the number of blocks to 120. They also have a complex way to cut up an array into subarrays. Well, for now I will cut up the array in equal sized chunks. If performance results are close, there is always the option to go into more complexity.
A distinguishing feature of the Billeter et al. loop is that is has a warp size stride. We might find it interesting to explore this feature further, so let’s use the following function.
template
__global__ void device_copy_kernel3(const T* d_in, T* d_out, const unsigned int seq_size)
{
const auto idx = blockIdx.x * blockDim.x + threadIdx.x;
// index within warp, the name lane refers to the hardware implementation
const auto lane = threadIdx.x % WARP_SIZE;
// global index for warp, sequence
const auto sidx = idx / WARP_SIZE;
// set sequence begin and end
const auto seq_begin = seq_size * sidx;
const auto seq_end = seq_begin + seq_size;
// copy the sequence
for (auto i = seq_begin + lane; i < seq_end; i += WARP_SIZE)
{
d_out[i] = d_in[i];
}
}
the seq_size parameter is defined as:
const unsigned int seq_size = ARRAY_SIZE / warp_cnt;
where warp_cnt is:
const unsigned int warp_cnt = (threads * blocks) / WARP_SIZE; // WARP_SIZE = 32
Benchmarks
Time measurements are averaged over 1000 calls of the kernel; Visual Studio release builds that are run without debugging, on an Asus Geforce GTX 690.
No loops
For the No loops case we cases we let the number of threads per block run from 32 – 1024 in steps of 32, the number of blocks is just ARRAY-SIZE / number-of-threads-per-block.
This gives us the following graph (I have subtracted 850 µs from each time measurement, in order to enhance the differences; all time measurements are larger than 850 µs).
There is a global minimum around the fourth measurement, i.e. in this experiment, the fourth measurement provides the best time performance.
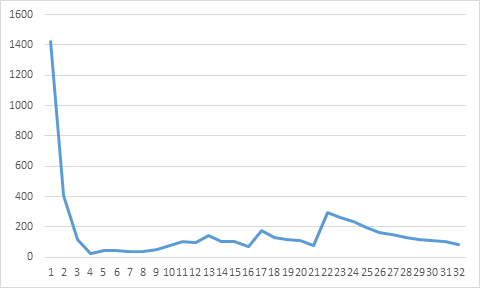
Grid stride loops
The Grid stride loop case has a huge number of possible parameter values, so we do a somewhat coarse search. The set of numbers of threads per block is {64, 128, 256, 512, 1024}. The parameter space for the number of blocks is divided into 32 values (where we disregard the case for zero blocks).
This gives us the following graph (I have again subtracted 850 µs from each time measurement).
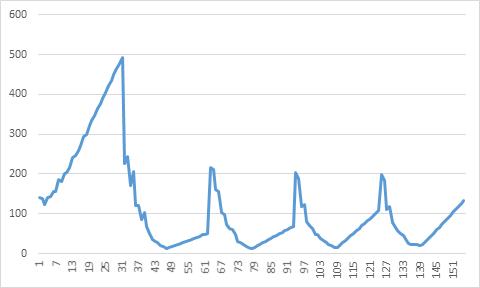
The are several, let’s say, regional minima: the 47th, 78th, 109th, and 139th measurement.
|
Measurement nr. |
Threads |
Blocks |
Time (µs) |
|
47 |
128 |
65,536 |
862.3 |
|
78 |
256 |
32,768 |
861.8 |
|
109 |
512 |
16,384 |
864.7 |
|
139 |
1024 |
7,680 |
871.2 |
Interestingly, this is a very regular series. The last measurement is just 1 step before the step with 8192 blocks (2 x 8192 = 16384).
Warp stride loops, Billeter et al. loops
Nvidia hardware executes a warp of threads in parallel on a single multiprocessor. So it makes sense to set up sequences that are processed by a single warp of threads. Such sequences are processed by warp stride loops. The number of warps then determines the number of sequences, hence their size. NVidia warns not to write programs that critically depend on the size of a warp. So, production software that uses the warp size as a parameter should always query the hardware at runtime to get the actual warp size (for the overseeable past and future expect it to be either 16, 32, or 64).
Billeter et al. have a warp stride loop with 120 blocks of 128 threads. I have measured the time performance and registered it in the table in the Summary section.
The time performance is not ultimately impressive: 1804.7 µs; the slowest option in the pack .
In order to see if the warp stride loop variant has any merits, I performed a parameter search, similar to the grid stride loop case. Note that the array length, the warp size, the number of threads per block, and the number of blocks together completely determine the size and number of sequences.
This resulted in the following graph (each measurement got again 850 subtracted).

The 47th measurement has the shortest time: 863.7 µs.
Summary
The best time performance and bandwidth results are in the table below.
|
Time (µs) |
Bandwidth (GB/s) |
Threads |
Blocks |
Sequence size |
|
| No Sequences |
870.9 |
154.1 |
128 |
131,072 |
– |
| Grid Stride Loops |
861.8 |
155.7 |
800 |
1,024 |
array size |
| Billeter et al. Sequences |
1,804.7 |
74.4 |
128 |
120 |
32,768 |
| Warp Stride Loops |
863.7 |
155.4 |
128 |
65,536 |
64 |
Time is in microseconds, so all results are about equal, except the Billeter et al. case which is significantly slower.
At this point we see no (dis)advantage of using sequences!
Vectorized Memory Access
Another question is if any of these alternatives can can benefit from using vectorized memory access [2]. The hardware can execute memory access operations on scalars, but also on small vectors of 2 components (pairs) or 4 components (quads). To see what the effects of vectorized memory access are, I adapted the software accordingly. Note that if the program processes vectors of e.g. 4 components, it need only 1/4th of the reads and writes of the scalar case.
Vectorized memory access with pairs
The test program proceeds just as described above. The table below summarizes the results obtained.
|
Time (µs) |
Bandwidth (GB/s) |
Threads |
Blocks |
Sequence size |
|
| No Sequences |
857.9 |
156.5 |
704 |
11,915 |
– |
| Grid Stride Loops |
859.7 |
156.1 |
1,024 |
8,192 |
array size |
| Billeter et al. Sequences |
1,434.6 |
93.6 |
128 |
120 |
17,464 |
| Warp Stride Loops |
820.9 |
163.5 |
256 |
38,912 |
26 |
It turns out that warp stride loops benefit most from vectorized memory access with pairs. This includes Billeter et al. sequences.
Vectorized memory access with quads
The table below summarizes the results obtained.
|
Time (µs) |
Bandwidth (GB/s) |
Threads |
Blocks |
Sequence size |
|
| No Sequences |
862.3 |
155.7 |
1,024 |
4,096 |
– |
| Grid Stride Loops |
862.4 |
155.6 |
64 |
65536 |
array size |
| Billeter et al. Sequences |
1,335.7 |
100.5 |
128 |
120 |
8738 |
| Warp Stride Loops |
831.7 |
161.4 |
256 |
38,912 |
26 |
So, it seems that vectorized memory access with quads, as opposed to pairs, is beneficial for Billeter et al. sequences, but not for the other options.
Conclusions
We conclude that warp stride loops offer the best performance. Better than using no loops, to be sure, if combined with vectorized memory access for pairs (not quads).
We have seen that the performance graphs of the various options show many local minima. So, it pays to do a search for the parameters that maximize performance.
Then, of course, there is the question whether sequences is what makes Billeter et al stream compaction the world champion. The answer is: Definitely not!
Addendum / Correction
<11-06-2018> Cleaning up the demo software I noticed that the Billeter et al. case had the code for setting up the sequences included in the time measurement section, whereas setting up sequences is a compile time activity in the original program by Billeter et al. So, when this is corrected, processing times become significantly better, 1125.3 µs (119.3 GB/s) for the scalar case, 1005.6 µs (133.5 GB/s) for pairs, and 1023.8 µs (131.1 GB/s) for quads respectively. Note however, that the general conclusions do not change.
Next
If the use of sequences does not set stream compaction according to Billeter et al. apart from the rest, then what does? Is it the difference in size the meta data volume?
References
[1] https://devblogs.nvidia.com/cuda-pro-tip-write-flexible-kernels-grid-stride-loops/
[2] https://devblogs.nvidia.com/cuda-pro-tip-increase-performance-with-vectorized-memory-access/ .
Demo code
You can download demo code from here
