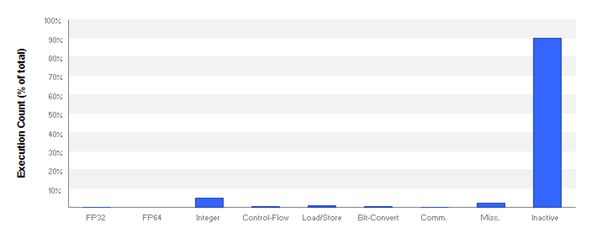
This is nr. 5 in a collection of blog posts on Parallel Stream Compaction. And this will be the final episode. In previous posts we saw that the implementation by Billeter, Olsson, and Assarsson is faster than implementations by Orange Owls and Spataro; a multiplicative relation holds for processing times, even over different graphics cards. We saw that the essential differences between the fastest algorithm, by Billeter et al., and the others, are that the former uses sequences, a very small data structure for metadata, and vectorized IO, and that the latter programs do not.
In the previous post we saw that in particular vectorized IO makes the performance difference between the slower and the faster programs.
This post discusses a somewhat modernized and optimized library for stream compaction, put together from code of different sources and my own efforts.
Modern constructs for Billeter et al.
The stream compaction code by Billeter et al. predates the Cuda __shfl_x constructs which allows for very concise scan and reduce functions. Thus, their program can be rearticulated in significantly shorter code. Taking their program as a starting point, along with code fragments from other sources, I have constructed another stream compaction program. The core algorithm takes about 150 lines of spacious code.
A disclamer is required here. I do not (yet) own the lastest Cuda capable hardware. So, there are modern constructs that are not applied, which would simplify the code and enhance its performance further. In particular, one might think of dynamic parallellism which would allow for a stream compaction algorithm without the construction and use of any metadata at all. On the other hand, this same modern hardware dwarfs the performance of my GeForce GTX 690, which would render further optimization pretty senseless.
Optimization
We have learned a number of lessons about optimal implementations of the various phases of stream compaction in the previous episodes of this series. This concerns using sequences, vectorized IO, threading configuration, and also the use of warp level primitives that eliminate some uses of shared memory in this program (namely to support inter thread, intra warp data exchange).
Applying these lessons leads to a stream compaction library that is even faster than Billeter et al.’s.
One somewhat brutal optimization is to eliminate the ability to process the exact size of the input stream. The library I pieced together from various sources requires an input stream which length is a multiple of 65.536 (2^16 = 64K). This seems a large number, but all is relative. First of all, if you have a small stream, compaction is just as well done using CPU code. If, on the other hand, you have a large input stream, even a number like 65.536 is only a small fraction of this large stream. For instance 65.536 x 19 = 1.245.184: a moderately large stream. Now, 64K is 5.3% of 1.245.184. If we take 65.536 x 20 = 1.310.720 instead, we have an overhead of 5.3% – 5% = 0.3%. Note that there may be a performance advantage in taking the larger size, see below.
How does this multiple of 64K come about? If you have a large stream, we will first divide it up into 512 sequences that are processed as concurrently as possible. Each sequence is read using uint4 vectorized IO, which divides its length by 4. The resulting chunk should be a multiple of the warp size (so it can be processed concurrently per warp). Then we have that 512 x 4 x 32 * i = 65.536 * i (i the multiple of 32). I found that the advantage of rounding up to the next multiple of 64K is pretty robust for very large streams.
The requirement that the input length is a 64K multiple is a consequence of the configuration of the algorithmic parameters, and a corresponding selection of code from the demo code into the library. The code can be customized to fit specific applications by changing the number of sequences and/or changing the level of vectorized IO. E.g. if you set the number of sequences to 1, and restrict to scalar IO, the requirement reduces to the input length being a multiple of the warp size (32 for now).
Comparison to Billeter et al.
So let’s go to the numbers. How do performances compare, overall, and for different phases? All measurements are for rand() data with a rand() % 2 choice for a nonzero (== valid) value.
N = 2^24.
| Phases | Billeter et al. (µs) | Current (µs) |
| Count |
453.15 |
445.45 |
| Prefix |
7.34 |
5.33 |
| Move |
964.27 |
835.56 |
| All |
1424.76 |
1286.34 |
So, the new library is a bit faster in all phases.
Other input sizes
Now let’s explore the performance of the library with other input sizes.
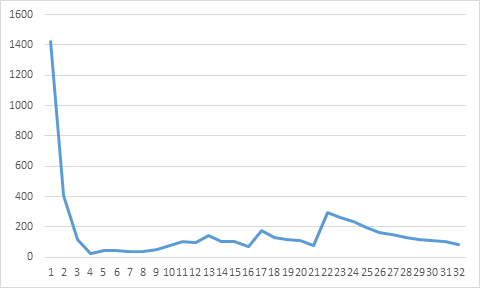
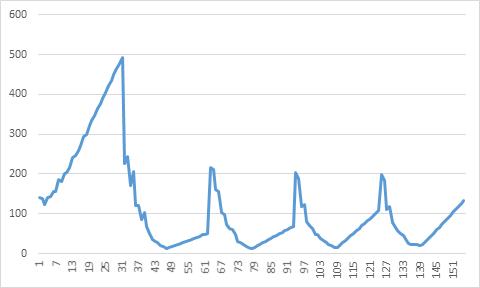
If we let the library process input stream of length 65536 * i with i = 1, …, 256 (65536 * 256 == 2^24), we may get the following graph.
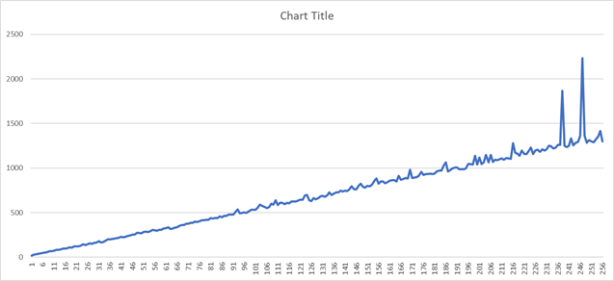
This is a kind of a surprise. I ran the program several times, and the results have a somewhat statistical character, but one or two peaks at the end of the x-axis are always there.
What do we see?
- For smaller values of the size we see a pretty regular development, but for some input lengths, processing times are shorter than for somewhat smaller lengths.
- For larger values, extreme differences in processing times between subsequent input sizes are possible.
So, it pays to see if a somewhat longer input length yields a shorter processing time. In case of rounding to the nearest multiple of 64K one can of course investigate whether adaptation of the algorithmic parameters and code selection provides better results.
Demo code
Below, two links to code are inserted. One link is to a demo program. This program has an IO variant for each phase. The other link is to the library, as discussed above. All code is currently for unsigned int.