Harder to C++: Monads for Mortals [5], Pointers
In part 2 we have seen a small and elegant implementation of the monad. In part 4 we have seen how references and move semantics can be used to make the monad’s performance independent of the size of the wrapped value. In this part we will see another implementation the monad based on a pointer.
Implementation of a Monad with a Smart Pointer
We have seen in part 2 that the type constructor is represented by a template in C++. In part 2 this is a simple struct, in part 3 it is a std::function holding a lambda expression – so as to implement delayed evaluation, and in this part, it is a smart pointer, the std::unique_ptr to be precise.
So, now the type constructor is:
// Monad type constructor template<typename T> using monad = unique_ptr<T>;
We do not use a separate unit function, the unique_ptr‘s constructor will do. The bind function is:
// Bitwise OR operator overload, Monad bind function
template<typename A, typename R>
monad<R> operator|(monad<A>& mnd, monad<R>(*func)(const A*))
{
log("---Function bind");
return func(mnd.get());
}
Since in the applied functions we do not manage the life cycle of the existing A object, we send in a raw pointer, not a smart pointer.
Given the simple functions we used earlier, this implementation of the monad is used as follows:
// divides arg by 2 and returns result as monadic template
monad<ValueObject> divideby2(const ValueObject* v)
{
log("---Function divideby2");
return monad<ValueObject>(new ValueObject(v->size() / 2));
}
// checks if arg is even and returns result as monadic template
monad<bool> even(const ValueObject* v)
{
log("---Function even");
return monad<bool>(new bool(v->size() % 2 == 0));
}
void valueobjectmain()
{
{
auto m1 = monad<ValueObject>(new ValueObject(16));
auto m2 = m1 | divideby2 | divideby2 | divideby2 | even;
cout << boolalpha << *m2 << endl;
}
}
The ValueObject class is the same as used in part 4.
Running the above code results in output:
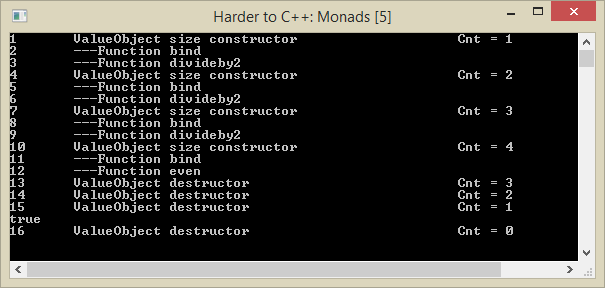
I think the most important result here is what we don’t see: calls to the move constructor and the accompanying call to the destructor of the ValueObject.
Pro’s, Con’s, and Questions
The above image of the output is nicely constrained. Functions return the unique_ptr by value, i.e. it gets copied which is ok, and the bind function takes a reference to a unique_ptr to elicit the raw pointer from. We see the calls to ValueObject destructor occur after assignment to m2, and when leaving the anonymous scope.
So, pro’s for this implementation are its simplicity, clarity, and efficiency: the overhead of a unique_ptr is comparable to the overhead of a raw pointer. Values are not copied, so performance is size independent.
You may wonder, though, whether it is a good idea to create all the monad’s values on the heap, which is not so efficient. In part 6 we take a look at what we have so far and see what works best.

[…] Harder to C++: Monads for Mortals 5, Pointers […]