Harder to C++: Monads for Mortals [7], Monad Composition
Early authors on monads, e.g. [Moggi], [Wadler], describe several types of monads, notably for side-effects, state, exceptions and IO. Of course we want to write programs that have all these features. There are, in principle, two possible approaches. First: write a separate monad each time we think up a new piece of non-pure-functional … (shall we dare call it functionality?). Second: compose different standard monads into larger wholes? In [part 2] of his excellent tutorial on monads Mike Vanier writes:
‘ Functional programmers talk about “composability” all the time, with the implication that if some aspect of a programming language isn’t composable, it’s probably not worth much.’
So, clearly composition is key and we will see some monads composed into larger wholes here. To be clear: I don’t mean function composition, I mean monad composition. In C++. To be precise, I will define:
- A monad that executes a function which maintains a state (side-effect).
- A monad that catches and handles exceptions.
- A monad that writes the result of function composition to console or an error message in case an exception occurred.
Then I will compose those monads into a larger whole, with preservation of imperative ‘functionality’. We will see that it actually works. Then I will show a very general imperative C++ function, that has the same functionality, and we will compare size and performance of both approaches.
Monad Composition
We will use a single monad template and instantiate it for a State type, an Exception type, and a std::cout wrapper. The monad template looks like this:
//V: wrapped value, S: state of some sort
template<typename V, typename S>
struct monad
{
V value;
S state;
monad(const V& v) : value(v) {}
monad(V& v) : value(std::move(v)) {}
monad(const V& v, const S& s) : value(v), state(s) {}
monad(V& v, S& s) : value(std::move(v)), state(std::move(s)) {}
monad(V&& v, S&& s) : value(std::move(v)), state(std::move(s)) {}
template<typename T, typename W>
monad(const monad<T, W>& m) : value(m.value), state(m.state) {}
monad(monad&& m) : value(std::move(m.value)), state(std::move(m.state)) {}
~monad() {}
monad& operator=(const monad& m)
{
if(this != &m)
{
value = m.value;
state = m.state;
}
return *this;
}
monad& operator=(monad&& m)
{
if(this != &m)
{
value = m.value;
m.value = V();
state = m.state;
m.state = mystate();
}
return *this;
}
};
The template consists of a wrapped value and a field to hold state of some sort, e.g. actual state, an exception, or an io stream. The rest of the code is just what is generally referred to as ‘copy control’.
The ‘S’ parameter will be instantiated using three classes: State, Exception, and Cout
struct State
{
int count = 1;
void update(const int seed) { count += seed; }
};
struct Exception : std::exception
{
Exception() : message(""), errorCode(0) {}
Exception(string msg, int errorCode) : message(msg), errorCode(errorCode) { }
string ErrorMessage() const
{
stringstream ost;
ost << message << " " << errorCode;
return ost.str();
}
private:
string message;
int errorCode;
};
struct Cout
{
ostream& os;
Cout() : os(cout) {}
};
Cout is a std::cout wrapper. We need it because io streams cannot be copied or assigned, but by the design of our monad template (S is not a reference or pointer) we need something that actually can be copied or assigned.
For the monad template we define three overloads of the bind function, one for each instantiation of the template:
// bind function overload: State
template<typename A, typename R>
monad<R, State> operator| (const monad<A, State>& mnd, monad<R, State>(*func)(const A&))
{
auto tmp = func(mnd.value);
tmp.state.update(mnd.state.count);
return tmp;
}
// bind function overload: Exception
template<typename A, typename R>
monad<R, Exception> operator| (const monad<A, Exception>& mnd, monad<R, Exception>(*func)(const A&))
{
try
{
return func(mnd.value);
}
catch(Exception& ex)
{
auto tmp = monad<R, Exception>(R(mnd.value));
tmp.state = ex;
return tmp;
}
}
// bind function overload: Cout
template<typename A, typename R>
monad<R, Cout> operator|(const monad<A, Cout>& mnd, monad<R, Cout>(*func)(const A&))
{
auto tmp = func(mnd.value);
// Need to create a new tmp, because we cannot assign, copy ostream.
// When initializing, we use a ref to ostream
auto tmp2 = monad<R, Cout>(tmp.value, mnd.state);
tmp2.state.os << tmp2 << endl;
return tmp2;
}
In the last bind function we see the familiar output operator. In order to make it work, we need overloads of this operator for the monad template, and the three auxiliary classes (or ‘structs’ if you like):
// << overload for monad
template<typename V, typename S>
ostream& operator<<(ostream& os, const monad<V, S>& m)
{
os << "Value: " << m.value << " State: " << m.state;
return os;
}
// << overload for State
ostream& operator<<(ostream& os, const State& s)
{
os << s.count;
return os;
}
// << overload for Exception
ostream& operator<<(ostream& os, const Exception& e)
{
if(e.ErrorMessage() != " 0")
os << e.ErrorMessage();
return os;
}
// << overload for Cout, more or less a dummy (but required)
ostream& operator<<(ostream& os, const Cout&)
{
os << "Cout";
return os;
}
The last thing we need is some function that can be applied by the bind functions. These functions cannot be type agnostic: the return type differs from the parameter type. So we have three overloads of them, and they do exactly the same. Let’s first define some handy type aliases:
typedef monad<int, State> is_monad; typedef monad<is_monad, Exception> ise_monad; typedef monad<ise_monad, Cout> isec_monad;
These typedefs nest a monad template instantiation, which is a type, within another. Now the functions to be used divide a number by 2:
is_monad divideby2(const int& i)
{
return is_monad(i / 2);
}
ise_monad divideby2(const is_monad& m)
{
if(m.value < 2)
// Somewhat artificial
throw Exception("Division by zero", -1);
auto m2 = m | divideby2;
return ise_monad(m2);
}
isec_monad divideby2(const ise_monad& m)
{
auto m2 = m | divideby2;
return isec_monad(m2);
}
As you can see, there is composition, but there is no generality. That is, monad composition is in fact ugly and painful and scaling is out of the question.
We run this, in a by now familiar way:
int _tmain(int argc, _TCHAR* argv[])
{
{
int i = 8;
is_monad m1(i);
ise_monad m3(m1);
isec_monad m5(m3);
auto m2 = m5 | divideby2 | divideby2 | divideby2 |divideby2;
}
cin.get();
return 0;
}
and get the result we desired:

After a code exposé of just 200 lines :-).
A Very Ordinary C++ Function
The same result (well, without of course the funny output that so points out recursion) can be obtained by the following function:
void VeryOrdinary()
{
int num = 8;
int cnt = 1;
try
{
for(unsigned int i = 0; i< 4; ++i)
{
num /= 2;
++cnt;
cout << "Value : " << num << " State: " << cnt << endl;
if(num < 2)
// Somewhat artificial
throw Exception("Division by zero", -1);
}
}
catch(Exception& ex)
{
cout << "Value : " << num << " State: " << cnt << " " << ex.ErrorMessage() << endl;
}
}
We run it by simply calling it:
int _tmain(int argc, _TCHAR* argv[])
{
SetConsoleTitle(L"Harder to C++: Monads [7]");
VeryOrdinary();
cin.get();
return 0;
}
And the result is:
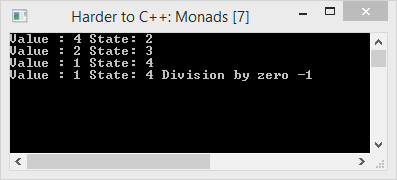
After a code exposé of 34 lines (it pays to remember the approximate factor of 6 for later).
Let’s compare the sizes of both approaches. Well, the monad composition is ridiculously much larger than the ordinary solution.
Performance
Performance measurements were set up in a way comparable to measurements in part 6: the code above is run a large number of iterations, and time is measured. This is done for 10 runs, and the average over the times is calculated. Before starting measurements, the monad composition is allowed a warming up run, to prevent an outlier. The default release build of the resulting program was run from a command console.
Now, time performance results are dominated almost completely by the use of std::cout and throwing exceptions. If both are used, or occur, times are comparable. If however, we do not log to the console, and have no exceptions thrown (we set value to 32), that is, we measure the performance at the naked difference of the constructed code, the regular code takes only 1.6% of the time the monad solution takes, i.e. the regular solution is about 60 times as fast, see the image below for a typical performance run.
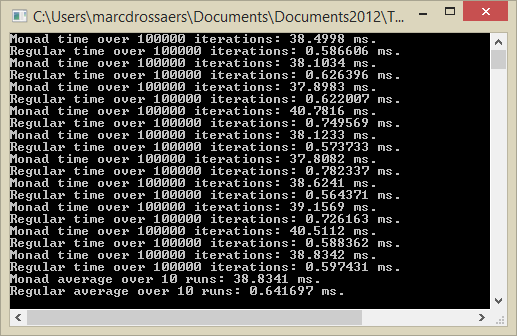
in this particular case the ordinary C++ function is 38.8 / 0.64 = 60.6 times as fast. The time it takes the regular function to execute is 100% x 0.64 / 38.8 = 1.6% of the time it takes the monad composition to execute. Please note that the variation in measured times is limited.
Conclusions
Let’s be brief. The code size and time performance of the monad composition are not in sensible proportion to size and performance of the regular function: 6 : 1 and 60 : 1 respectively. The code size of monad composition is ridiculous, monad composition kills C++ performance.
Wrap Up of Sequential Monads
We are a now at the end of 7 installments experimenting with monads, so let’s wrap up what we have so far. The question is: “Can monads be useful in day-to-day C++ programming?”. And the answer is “No”.
We have looked briefly at a C++ template meta programming (which constitutes a simple functional language) approach. The disadvantages are:
- Complex syntax, hence diminished simplicity and clarity (one day your code will be maintained by another developer!)
- Although it is possible to use this approach, the language does not support it. So it is unreasonably hard. (free after Stroustrup’s argument that OO development is possible in C, or assembly, but the language… )
- There are no debugging facilities, which makes it very hard to develop substantial amounts of code as meta programs.
We have seen a simple and short implementation of the monad in mainstream C++. However, this implementations has the drawback that its performance dies if it is applied to large data structures.
The drawback could be remedied by replacing the unit function by a complete copy control set for the monadic template.
Lazy monads can be elegantly implemented as well, but they have no performance whatsoever, due to the fact that code is evaluated twice, once to create the expression to evaluate, and another time to indeed evaluate the expression.
Furthermore, we have seen, in this episode that if we want to write somewhat larger programs using monad composition, we get very large programs without performance.
I think I’m done now with at least the sequential monad. I have no further interest. It is tedious, needlessly complicated, and leading to inefficient results when trying to construct meaningful programs from different monads in C++.
I wrote ‘sequential monad’ above, because there is still the continuation monad to investigate; the suggested solution to Callback Hell in concurrency contexts. So, for starters, what exactly is Callback Hell? We will see in part 8.
