A Jitter Filter for the Kinect
This blog post introduces a filter for the jitter caused by the Kinect depth sensor. The filter works essentially by applying a dynamic threshold. Experience shows that a threshold works much better than averaging, which has the disadvantage of negatively influencing motion detection, and has only moderate results. The presented DiscreteMedianFilter removes the jitter. A problem that remains to be solved is the manifestation of depth shadows. Performance of the filter is fine. Performance is great in the absence of depth shadow countermeasures.
Introduction
Kinect depth images show considerable jitter, see e.g. the depth samples from the SDK. Jitter degrades image quality. But it also makes compression(Run Length Encoding) harder; compression for the Kinect Server System will be discussed in a separate blog post. For these reasons we want to reduce the jitter, if not eliminate it.
Kinect Depth Data
What are the characteristics of Kinect depth data?
Literature on Statistical Analysis of the Depth Sensor
Internet search delivers a number of papers reporting on thorough analysis of the depth sensor. In particular:
[1] A very extensive and accessible technical report by M.R. Andersen, T. Jensen, P. Lisouski, A.K. Mortensen, M.K. Hansen, T. Gregersen and P. Ahrendt: Kinect Depth Sensor Evaluation for Computer Vision Applications.
[2] An also well readable article by Kourosh Khoshelham and Sander Oude Elberink.
[3] A more technically oriented article by Jae-Han Park, Yong-Deuk Shin, Ji-Hun Bae and Moon-Hong Baeg.
[4] Of course, there is always the Wikipedia
These articles discuss the Kinect 360. I’ve not found any evidence that these results do not carry over to the Kinect for Windows, within the range ([0.8m – 4m]) of the Default mode.
Depth Data
We are interested in the depth properties of the 640×480 spatial image that the Kinect produces at 30 FPS in the Default range. From the he SDK documentation we know that the Kinect provides depth measurements in millimeters. A dept value measures the distance between a coordinate in the spatial image and the corresponding coordinate in the parallel plane at the depth sensor, see image below from the Kinect SDK Documentation.
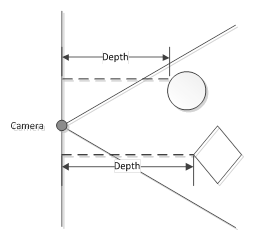
Some characteristics:
1. Spatial resolution: at 0.8m the 640×480 (width x height) depth coordinates cover an approximately 87cmx63cm plane. The resolution is inversely proportional with the squared distance from the depth sensor. The sensor has an angular field of view of 57° horizontally and 43° vertically.
2. Depth resolution: the real world distance between 2 subsequent depth values the Kinect can deliver is about 2mm at 1m from the Kinect, about 2.5cm at 3m, and about 7cm at 5m. Resolution decreases quadratically as a function of the distance.
Jitter
The Kinect depth measurements are characterized by some uncertainty that is expressible as a random error. One can distinguish between errors in the x,y-plane on the one hand, and on the z-axis (depth values) on the other hand. It is the latter that is referenced to as the depth jitter. The random error in the x,y-plane is much smaller than the depth jitter. I suspect it manifests itself as the color jitter in the KinectColorDepthServer through the mapping of color onto depth, but that still has to be sorted out. Nevertheless, the filter described here is also applied to the color data, after mapping onto depth.
The depth jitter has the following characteristics:
1. The error in depth measurements: The jitter is about a few millimeters at 0.5m, up to 4cm at 5m, increasing quadratically over the distance from the camera.
2. The jitter is a walk over a small number of nearby discrete values. We have already seen this in a previous post in The Byte Kitchen Blog, where we found a variance over mainly 3 different values, and incidentally 4 different values. Of course, for very long measuring times, we may expect an increased variance.
3. The jitter is much larger at the boundaries of depth shadows. Visually, this is a pretty disturbing effect, but the explanation is simple. The Kinect emits an infra red beam for depth measurements which, of course, creates a shadow. The jitter on the edges of a depth shadow jumps from an object to its shadow on the background which is usually much further away. We cannot remove this jitter without removing the difference between an object and its background, so for now, I’ve left it as is.
The miniature below is a link to a graph in [2] (page 1450, or 14 of 18) of the depth resolution (blue) and size of the theoretical depth measurement error (red).

A Kinect Produces a Limited Set of Discrete Depth Values
It is not the goal of the current project to correct the Kinect depth data, we just want to send it over an Ethernet network. What helps a lot is, and you could see this one coming:
The Kinect produces a limited set of depth values.
The Kinect for Windows produces 345 different depth values in the Default range, not counting the special values for unknown, and out of range measurements. The depth values for my Kinect for Windows are (divide by 8 to get the depth distance in mm):

This is the number of values for the Kinect for Windows. I also checked the number of unique values for my Kinect 360, and it has a larger but also stable set of unique depth values. The number of depth values is 781, due to the larger range.
The fact that a Kinect produces a limited and small set of depth values makes live a lot easier: we can use a lookup table were we would otherwise have to use function approximation. The availability of a lookup table is also good news for the time performance of the filter.
A question might be: can you use the depth table of an arbitrary Kinect to work with any other Kinect? I assume that each Kinect has a slightly different table, and this assumption is based on the fact that my Kinect for Windows has slightly different values than my Kinect 360, for the same sub range. However, if you use an upper bound search (this filter uses std::upper_bound), you will find the first value equal to or larger than a value from an arbitrary Kinect, which will usually be a working approximation (better than having the jitter). Of course, an adaptive table would be better, and it is on the ToDo list.
Design
I’ve experimented with several approaches: sliding window of temporal averages, Bilateral Filter. But these were unsatisfactory:
– Reduction of Jitter is much less good compared to applying a threshold.
– Movement detection is as much reduced as the jitter, which is an undesirable effect.
A simple threshold, of about the size of the breadth of the error function proved the best solution. As noted above, the jitter typically is limited to a few values above and below the ‘real’ value. We could call the ‘real’ value the median of the jitter range, and describe this jitter range not in terms of the depth values themselves but of the enumeration of the sorted list of discrete depth values (see table). We get a Discrete Median Filter if we map all discrete values within the range onto the median of that range (minding the asymmetry of the sub ranges at the boundaries of our sorted list).
The DiscreteMedianFilter Removes Jitter
In practice we see no jitter anymore when the filter is applied: The DiscreteMedianFilter ends the jitter (period). However, the filter is not applicable to (edges of) depth shadows.
Noise
Actually, it turned out that this filter is in fact too good. If the Kinect registers a moving object, we get a moving depth shadow. The filter cannot deal with illegal depth values, so we are stuck with a depth shadow smear.
A modest level of noise solves this problem. In each frame 10% of the pixels the filter skips is selected at random, and updated. This works fine, but it should be regarded as a temporal solution: the real problem is, of course, the depth shadow, and that should be taken up.
Implementation
The Discrete Median Filter was implemented in C++, as a template class, with a traits template class (struct, actually); one specialization for the depth value type and one specialization for the color value type, to set the parameters that are typical for each data type, and a policy template which holds the variant of the algorithm that is typical for the depth and color data respectively. For evaluation purposes, I also implemented traits and policy classes for unsigned int.
So, the DiscreteMedianFilter class is a template that takes a value type argument. Its interface consists of a parameter free constructor and the Filter method that takes a pointer to an input array and a pointer to a state. The method changes the state where the input deviates from the state more than a specified radius.
Channels and Offset
Color data is made up of RGBA data channels: e.g. R is a channel. Working with channels is inspired on data compression. More on this subject in the blog post on data compression.
The advantages of working with channels for the DiscreteMedianFilter are:
1. We can skip the A channel since it is all zeroes
2. Per channel, changes of color due to sensor errors are usually expressible as small changes, which is not the case for the color as a whole, so we get better filtering results.
3. There are less values: 3 x 256 vs 2^32, so the probability of equal values is higher.
Note that the more values are found to be within the range of values that do not need change, the better time performance we get.
The individual channels are not processed in parallel (unlike in the compression library). We will show below that parallelism should not be required (but actually is, as long as we have noise).
Code
The code is complex at points, so it seems to me that printing the code here would raise more questions than it would answer. Interested people may download the code from The Byte Kitchen Open Sources at Codeplex. If you have a question about the code, please post a comment.
Performance
How much space and time do we need for filtering?
A small test program was built to run the filter on a number of generated arrays simulating subsequent depth and color frames. The program size never gets over 25.4 megabytes. The processing speed (without noise) is:
– About 0.77ms for an array of 1228800 bytes (640×480=307200 ARGB color values); 1530Mbyte/s
– About 0.36ms for an array of 640×480=307200 unsigned short depth values; 1615Mbyte/s.
So, this is all very fast, on a relatively small footprint: in a little more than 1ms we have filtered both the depth and the color data of a Kinect frame.
The simple test program and its synthetic data are not suitable for use with noise. So, we measured the time the KinectColorDepthServer needs for calls to the DiscreteMedianFilter. In this case the noise is set at 10% of the values that would otherwise be skipped. The times below are averaged over 25,000 calls:
– Depth: 6.7ms per call.
– Color: 19.3ms per call.
So, we may conclude that the noise is really a performance killer. Another reason to tackle the depth shadow issue. Nevertheless, we are still within the 33ms time window that is available for each frame at 30 FPS.
Does the DiscreteMedianFilter has any effect on the required network capacity? No, in both cases a capacity of 460Mbit/s is required for a completely static scene, compression is off. I do have the impression that the filter has a smoothing effect on instantaneous (as opposed to average) required network capacity.
To do
There is always more to wish for, so what more do we want?
– Resolve the need for the noise factor, i.e. do something about the depth shadows. This will increase performance greatly.
– Because of filtering, navigation through the scene is jerky. There are much less depth values in the image, so movement is not so smooth. This is to be helped by sending a full depth image every now and then. After all, the filter only replaces values that differ more than a threshold, the rest of the image is retained. Refreshing the overall picture now and then retains the richness of the depth image, helps to make noise superfluous, and smoothes navigation.
– Make the table of depth values adaptive. If a value is not present we replace the nearest value. Of course, we would then also like to save the new table to file, and load it at any subsequent program starts.





























 Well, that is not entirely true. Couldn’t resist the temptation to add a slider (and a data bound TextBox that shows the value) that controls the rotation speed and direction of the cube.
Well, that is not entirely true. Couldn’t resist the temptation to add a slider (and a data bound TextBox that shows the value) that controls the rotation speed and direction of the cube.
