Data Compression for the Kinect
Transmitting uncompressed Kinect depth and color data requires a network bandwidth of about 460Mbit/s. Using the RleCodec or the LZ4 library we achieve tremendous compression – a compression ratio of 10 or 22 respectively, at lightning speed – over 1600Mbytes/s. We achieve this not so much by the compression algorithms, but by removing undesirable effects (jitter, by the DiscreteMedianFilter) and redundancy (already sent data, by taking the Delta).
Introduction
From the start, one goal of the Kinect Client Server (KCS) project was to provide a version of the KCS viewer, called 3D-TV, from the Windows Store. Because of certification requirement 3.1 (V5.0)
“Windows Store apps must not communicate with local desktop applications or services via local mechanisms,..”
3D-TV has to connect to a KinectColorDepth server application on another PC. In practice, the network bandwidth that is required to transfer uncompressed Kinect depth and color data over Ethernet LAN using TCP is about 460Mbit/s, see e.g. the blog post on the jitter filter. This is a lot, and we would like to reduce it using data compression.
This is the final post in a series of three on the Kinect Client Server system, an Open Source project at CodePlex, where the source code of the software discussed here can be obtained.
What Do We Need?
Let’s first clarify the units of measurements we use.
Mega and Giga
There is some confusion regarding the terms Mega and Giga, as in Megabit.
- For files 1 Megabit = 2^20 bits, and 1 Gigabit = 2^30 bits.
- For network bandwidth, 1 megabit = 10^6 bits, and 1 gigabit = 10^9 bits.
Here we will use the units for network bandwidth. The Kinect produces a color frame of 4 bytes and a depth frame of 2 bytes at 30 frames per second. This amounts to:
30 FPS x 640×48 resolution x (2 depth bytes + 4 color bytes) x 8 bits = 442.4 Mbit/s = 55.3 Mbyte/s.
We have seen before that the actual network bandwidth is about 460Mbit/s, so network transport creates about 18Mbit/s overhead, or about 4%.
Since we are dealing with data here that is streamed at 30 FPS, time performance is more important than compression rate. It turns out that a compression rate of at least 2 (compressed file size is at most 50% of uncompressed size), in about 5ms satisfies all requirements.
Data Compression: Background, Existing Solutions
Theory
If you are looking for an introduction to data compression, you might want to take a look at Rui del-Negro’s excellent 3 part introduction to data compression. In short: there are lossless compression techniques and lossy compression techniques. The lossy ones achieve better compression, but at the expense of some loss of the original data. This loss can be a nuisance, or irrelevant, e.g. because it defines information that cannot be detected by our senses. Both types of compression are applied, often in combination, to images, video and sound.
The simplest compression technique is Run Length Encoding, a lossless compression technique. It simply replaces a sequence of identical tokens by one occurrence of the token and the count of occurrences. A very popular somewhat more complex family of compression techniques is the LZ (Lempel-Ziv) family (e.g. LZ, LZ77, LZ78, LZW) which is a dictionary based, lossless compression. For video, the MPEG family of codecs is a well known solution.
Existing Solutions
There are many, many data compression libraries, see e.g. Stephan Busch’s Squeeze Chart for an overview and bench marks. Before I decided to roll my own implementation of a compression algorithm, I checked out two other solutions: The Windows Media Codecs In Window Media Foundation. But consider the following fragment from the Windows Media Codecs documentation:

It seems as if the codecs are way too slow: max 8Mbit/s where we need 442Mbit/s. The WMF codecs obviously serve a different purpose.
The compression used for higher compression levels seems primarily of the lossy type. Since we have only 640×480 pixels I’m not sure whether it is a good idea to go ‘lossy’. It also seems that not all versions of Windows 8 support the WMF.
LZ4, an open source compression library. This is a very fast compression library, see image below, from the website:
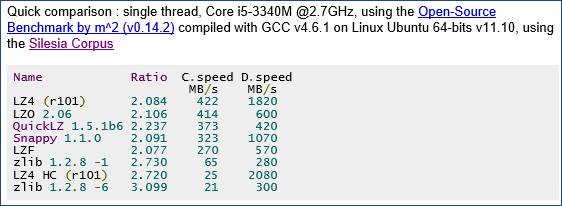
So, LZ4 can compress a file to 50% at over 400MByte/s. That is absolutely great! I’ve downloaded the source and tried it on Kinect color and depth data. Results are shown and compared in the Performance section.
The RleCodec
I decided to write my own data compression codec, and chose the Run Length Encoding algorithm as a starting point. Why?
Well, I expected a custom algorithm, tailored to the situation at hand would outperform the general purpose LZ4 library. And the assumption turned out to be correct. A prototype implementation of the RleCodec supported by both the DiscreteMedianFilter and creating a Delta before compressing data really outperformed the LZ4 reference implementation, as can be read from the performance data in the Performance section.
It only dawned on me much later that removing undesired effects (like jitter, by the DiscreteMedianFilter) and redundant information (already sent data, by taking the Delta) before compressing and transmitting data is not an improvement of just the RLE algorithm, but should be applied before any compression and transmission takes place. So, I adjusted my approach and in the performance comparison below, we compare the core RLE and LZ4 algorithms, and see that LZ4 is indeed the better algorithm.
However, I expect that in time the data compression codec will be implemented as a GPU program, because there might be other image pre-processing steps that will also have to be executed at the GPU on the server machine; to copy the data to the GPU just for compression requires too much overhead. It seems to me that for GPU implementations the RLE algorithm will turn out the better choice. The LZ4 algorithm is a dictionary based algorithm, and creating and consulting a dictionary requires intensive interaction with global memory on the GPU, which is relatively expensive. An algorithm that can do its computations purely locally has an advantage.
Design
Lossless or Lossy
Shall we call the RleCodec a lossy or lossless compression codec? Of course, RLE is lossless, but when compressing the data, the KinectColorDepth server also applies the DiscreteMedianFilter and takes the Delta with the previous frame. Both reduce the information contained in the data. Since these steps are responsible for enormous reduction of compressed size, I am inclined to consider the resulting library a lossy compression library, noting that it only looses information we would like to lose, i.e. the jitter and data we already sent over the wire.
Implementation
Algorithm
In compressing, transmitting, and decompressing data the KinectColorDepth server application takes the following steps:
- Apply the DiscreteMedianFilter.
- Take the Delta of the current input with the previous input.
- Compress the data.
- Transmit the data over Ethernet using TCP.
- Decompress the data at the client side.
- Update the previous frame with the Delta.
Since the first frame has no predecessor, it is a Delta itself and send over the network as a whole.
Code
The RleCodec was implemented in C++ as a template class. Like with the DiscreteMedianFilter, traits classes have been defined to inject the properties that are specific to color and depth data at compile time.
The interface consists of:
- A declaration that take the value type as the template argument.
- A constructor that takes the number of elements (not the number of bytes) as an argument.
- The size method that returns the byte size of the compressed data.
- The data method that returns a shared_ptr to the compressed data.
- The encode method that takes a vector of the data to compress, and stores the result in a private array.
- The decode method that takes a vector, of sufficient size, to write the decompressed data into.
Like the DiscreteMedianFilter, the RleCodec uses channels and an offset to control the level of parallelism and to skip channels that do not contain information (specifically, the A (alpha or opacity) channel of the color data). Parallelism is implemented using concurrency::parallel_for from the PPL library.
Meta Programming
The RleCodec contains some meta programming in the form of template classes that roll out loops over the channels and offset during compilation. The idea is that removing logic that loops over channels and checks if a specific channel has to be processed or skipped will provide a performance gain. However, it turned out that this gain is only marginal (and a really thin margin 🙂 ). It seems as if the compiler obviates meta programming, except perhaps for very complicated cases.
Performance
How does our custom RLE codec perform in test environment and in the practice of transmitting Kinect data over a network? How does its performance compare to that of LZ4?. Let’s find out.
In Vitro Performance
In vitro performance tests evaluate in controlled and comparable circumstances the speed at which the algorithms compress and decompress data.
Timing
In order to get comparable timings for the two codecs, we measure the performance within the context of a small test program I wrote, the same program is used for both codecs. This makes the results comparable and sheds light on the usefulness of the codec in the context of transmitting Kinect data over a network.
Algorithm
In comparing the RleCodec and LZ4, both algorithms take advantage of working the delta of the input with the previous input. We use 3 subsequent depth frames and 3 subsequent color frames for a depth test and a color test. In a test the frames are processed following the sequence below:
- Compute delta of current frame from previous frame.
- Compress the delta.
- Measure the time it takes to compress the delta
- Decompress the delta
- Measure the time it takes to decompress the delta
- Update previous frame with the delta
- Check correctness, i.e. the equality of the current input with the updated previous input.
We run the sequence 1000 times and average the results. Averaging is useful for processing times, the compression factor will be the same in each run. The frames we used are not filtered (DiscreteMedianFilter).

Let’s first establish that the performance of these libraries are of very different order than the performance of the WMF codecs. Let’s also establish that compression speed and decompression speed is much more than sufficient: as noted above 50Mbyte/s would do.
For depth data, we see that the RleCodec delivers fastest compression. LZ4 delivers faster decompression, and obtains stronger compression.
The RleCodec was tested twice with the color data. In the first test we interpreted the color data as of type unsigned char. We used 3 channels with offset 4 to compress it. In the second test we interpreted the color data as unsigned int. We used 4 channels, with offset 4. We see that now the RleCodec runs about 4 times as fast as with char data. The compression strength is the same, however. So, for color data, the same picture arises as with depth data: times are of the same order, but LZ4 creates stronger compression.
The difference in naked compression ratios has limited relevance, however. We will see in the section on In Vivo testing that the effects of working with a Delta, an in particular of the DiscreteMedianFilter dwarfs these differences.
We note that the first depth frame yields lesser results both for time performance and compression ratio. The lesser (de)compression speed is due to the initialization of the PPL concurrency library. The lesser compression ratio is illustrative of the effect of processing a Delta: the first frame has no predecessor, hence there is no Delta and the full frame is compressed. The second frame does have a Delta, and the compression ratio improves by a factor of 2.4 – 2.5.
In Vivo Performance
In Vivo tests measure, in fact, the effect of the DiscreteMedianFilter on the data compression. In Vivo performance testing measures the required network bandwidth in various configurations:
- No compression, no filter (DiscreteMedianFilter).
- With compression, no filter.
- With compression, with filter, with noise.
- With compression, with filter, without noise.
We measure the use of the RleCodec and the LZ4 libraries. Measurements are made for a static scene. Measuring means here to read values from the Task Manager’s Performance tab (update speed = low).
Using a static scene is looking for rock bottom results. Since activity in the scene- people moving around can be expressed as a noise level, resulting compression will always be somewhere between the noiseless level and the “no compression, no filter” level. Increase will be about linear, given the definition of noise as a percentage of changed pixels.
The measurements in the table below are in Megabits per second, whereas the table above shows measurements in Megabytes per second. So, in order to compare the numbers, if so required, the entries in the table below have to be divided by 8. Note that 460Mbit/s is 57.5Mbyte/s.
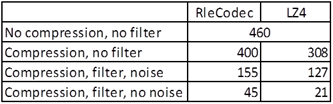
What we see is that:
- Compression of the delta reduces network bandwidth width 13* (RLE), or 33% (LZ4).
- Application of the filter reduces it further with 53% (RLE), or 39% (LZ4).
- Cancelling noise reduces it further with 24% (RLE), or 23% (LZ4).
- We end up with a compression factor of about 10 (RLE), or 22 (LZ4).
:-).
What do we transmit at the no noise level? Just the jitter beyond the breadth of the DiscreteMedianFilter, a lot of zeroes, and some networking overhead.
As noted above, the differences between the core RleCodec and LZ4 are insignificant compared to the effects of the DiscreteMedianFilter and taking the Delta.
Conclusions
Using the RleCodec or the LZ4 library we achieve tremendous compression, a compression ratio of 10 or 22 respectively , at lightning speed – over 1600Mbytes/s. We achieve this not so much by the compression algorithms, but by removing undesirable effects (jitter, by the DiscreteMedianFilter) and redundancy (already sent data, by taking the Delta).
ToDo
There is always more to wish for, so what more do we want?
Navigation needs to be improved. At the moment it is somewhat jerky because of the reduction in depth information. If we periodically, say once a second, send a full (delta yes, filter no) frame, in order to have all information at the client’s end, we might remedy this effect.
A GPU implementation. Compute shader or C++ AMP based. But only in combination with other processing steps that really need the GPU.
Improve on RLE. RLE compresses only sequences of the same token. What would it take to store each literal only once, and insert a reference to the first occurrence at reencountering it? Or would that be reinventing LZ?














 Well, that is not entirely true. Couldn’t resist the temptation to add a slider (and a data bound TextBox that shows the value) that controls the rotation speed and direction of the cube.
Well, that is not entirely true. Couldn’t resist the temptation to add a slider (and a data bound TextBox that shows the value) that controls the rotation speed and direction of the cube.










 decoration results in a clean export of the function names. Without the decoration, the C++ compiler will add a number of tokens (among which at least a few like @#$%^&*) to the function name in order to make it unique. The problem with this is that you’ll have a hard time retrieving the actual function name for use in the Silverlight client.
decoration results in a clean export of the function names. Without the decoration, the C++ compiler will add a number of tokens (among which at least a few like @#$%^&*) to the function name in order to make it unique. The problem with this is that you’ll have a hard time retrieving the actual function name for use in the Silverlight client.



 And a call of this function, in the MainPage_Loaded event handler:
And a call of this function, in the MainPage_Loaded event handler: Where DllPath is just the path specified above. Is that all? Yes, that’s all.
Where DllPath is just the path specified above. Is that all? Yes, that’s all.







