CX Reconsidered [3]: Components on a Thread
This is a series of blog posts that explore programming tactics which ascertain ‘a thin layer of CX’, as advertised and advised by Microsoft, and that thus maximize the use of ISO C++11(+).
This installment is about different approaches to having a component do its own thread management, and starts off by looking at various ways an application can be started up – assuming that different startup mechanics will lead to different ownership relations between an application and a component, hence different approaches to thread management.
This installment also considers some idioms involving C++11 concurrency, as defined in <thread> and <mutex>.
Introduction
It has been argued earlier in this series that threads are a vehicle by which CX dependencies, hence CX code constructs, propagate through your code. To stop this propagation (and preserve portability) we would like the Core component (the ISO C++ only area) to manage its own threads, and to run its operations on the threads its manages. This implies, so it seems, that for starters a component should not be instantiated on a CX thread.
We will consider several alternatives for starting a Xaml + CX application and find that one alternative stands out. We then discuss two models for thread management, and select the best fit. Finally we will walk through an example program.
Alternative Main() Functions
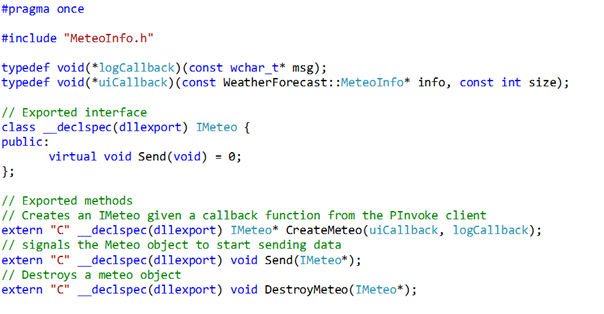
Each CX application has, just like each C# application, a main() function. In CX applications, the main() function is located in <Project Directory>Generated FilesApp.g.hpp, and it is decorated with “#ifndef DISABLE_XAML_GENERATED_MAIN”. So, if you as a developer define DISABLE_XAML_GENERATED_MAIN, and provide a custom main() function, your main() function will be called.
Steps to move to a custom main() function:
1. Add “#define DISABLE_XAML_GENERATED_MAIN” to the pch.h file.
2. Copy the main function from the App.g.hpp, to have a starting point.
3. Add a file, e.g. Main.cpp with the following code:

4. Then edit the main() function to suit your needs.
The standard main() function starts the Xaml application and instantiates an App class.
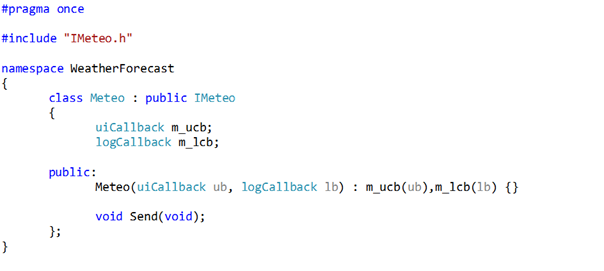
It is a conceivable scenario that along the App class a component is initialized, and a handle is passed to the App. The other way round is conceivable also: a handle to the App is passed to the Component.
Enumerating the alternatives systematically results in the following list, assuming that the component has an interface called ComponentClass:
1. Xaml owns all. The standard main() function instantiates the App class. In turn the App class instantiates the ComponentClass. Recall that App.g.hpp is generated, we cannot edit it meaningfully to initiate the ComponentClass.
2. Xaml owns the App. The standard main() function instantiates the App class, and calls a factory method in the component which instantiates the ComponentClass on a new thread.
3. App owns all. A custom main() function instantiates the Xaml UI, the App class and the ComponentClass, preferably on two threads.
4. App owns Xaml. A custom main() function instantiates the Xaml UI and the App class, and calls a factory method in the component which instantiates the ComponentClass on a new thread.
To have ownership means (here) to control the life cycle.
So, the summarize: using the standard main() function implies the Xaml UI owns the App class. Using a custom main() function implies the application owns the Xaml UI. In both cases there are two alternatives concerning ownership of the component: the owner also owns the component, or the component owns itself.
Central ownership reduces the number of threads involved, which simplifies data exchange. Decentralized ownership improves process stability, portability, and it keeps the CX layer thin.
We are primarily interested in alternatives in which the component does its own thread management, i.e. alternative 2. and 4. We conclude that a custom main() function does not add a relevant shift in ownership for our purposes and choose alternative 2. because it is simpler than 4.
Active Object or Asynchronous Programming?
How do you implement a component that runs on its own thread(s)? Well, I did some research and contemplated a bit on what I found, and now think there are two major approaches: the Active Object Pattern (Douglas C. Schmidt et al.), and some form of an Asynchronous Programming Model.
The Active Object Pattern
Central in this pattern by is a scheduler that dispatches methods corresponding to request messages on a queue that originated at external clients. Method execution can be asynchronous. (the image is a hyperlink to its source)

The following example implementation of the scheduler is proposed in the article (image is hyperlink):
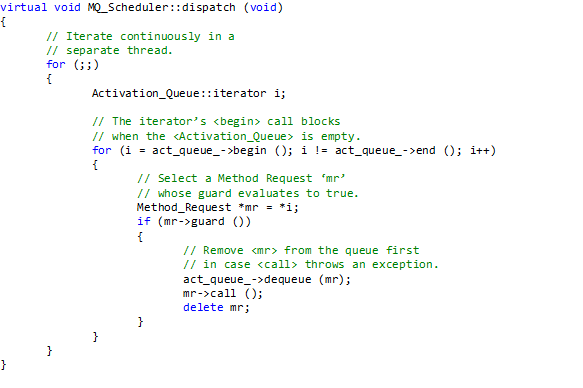
As the comment in the code above mentions: the scheduler runs on its own thread.
What to think of this? To me it seems the Active Object pattern is a very thorough but heavyweight solution. I think it is less suitable for the current challenge. Central in the pattern is a message processing loop, that continuously consumes processor cycles. This is a solution for an environment that lacks just this kind of infrastructural facilities. Windows, iOS, OSX, Linux, or Android GUI platforms are not such type of environments; they (still) have a message loop that continuously consumes processor cycles. To me it seems better to keep it at one such a glutton.
Recently I also stumbled upon a criticism by Bjarne Stroustrup. In his keynote at Going Native 2013 he classified a central scheduler as a performance bottleneck; he sketched a scenario of a significant number of potent parallel processors waiting for this one scheduler to provide some work from a well stocked queue.
So, we would like a solution that is more of a flyweight, and inherently concurrent as well.
A Singleton of Asynchronous Methods
A Singleton class is a pretty perfect implementation of the concept of Component. In C++ it gets instantiated at first use, and gets destructed at program termination. If so required, a reset method can be implemented that returns the state of the object to startup values. In a sense you could say that a Singleton holds its own destiny, just like an Active Component eating away cycles. The Singleton does this by holding a private static handle to its single object. No other entity (except friends, if any) can get to it.
The advantage of a Singleton over an Active Component is in particular (in this discussion) that it does not consume any processor cycles when not executing any tasks. Moreover, it can be made concurrent to any required extent. Here we will propose an asynchronous programming (callback variant) approach. So, we cannot say that the component runs on its own thread; there is no ‘engine’ explicitly running in the component. But, we do can say that the component does its own thread management if it is capable of running its operations on threads it controls.
Some Details
Operations in the context of GUI driven programs generally are functions, properties (get, set methods) and callbacks (event handlers).
In implementing IoC with DI we will implement an asynchronous method call as an interface method that delegates the work to be done to another thread, that provides a callback to return results or error information (the caller has to provide the callback), and then immediately returns.
Events can be raised on either the component generated thread an event raising operation is running on, or on a dedicated thread.
The get and set methods implementing properties should, I think, be so simple to not warrant asynchronism. These simple methods, primarily only getting an setting private fields, do should synchronize access to the fields they interface to.
A component as described here may require a substantial amount of threads, in little time. In order to be able to provide these threads timely, the component may maintain a thread pool, or rather, a thread queue where it keeps a stock of ready to use threads.
The following example might seem an overkill of asynchronicity. In that case it is important to keep three statements in mind:
1. This is the era of asynchronous programming. So , programming constructs that provide asynchronicity will be visible.
2. The example is densely filled with asynchronous constructs due to its instructive nature.
3. The exemplified class is an interface class. It is responsible for thread management, hence a focal point of asynchronous constructs. It thus frees other classes, deeper in the component from such constructs.
Example Application
To show the above described principles at work, we will present a demo application. This demo application centers around a Joke-of-the-Day component. You can:
– Request a random joke from the seemingly endless collection of jokes available to the component (property get() function).
– Add a joke to the collection (property set() function). When you add a joke to the collection, interested subscribers immediately are send your joke (raising an event).
– Request a stand-up session. During a client specified period, jokes are presented at small random intervals (string callback). The time remaining for the session is reported at fixed intervals (primitive type callback).
The component is an ISO C++ static lib, suitable for use in a CX component or app.
The complete example application is available from here. In this section we explore a few highlights dealing with lifecycle management and thread management.
Singleton Pattern
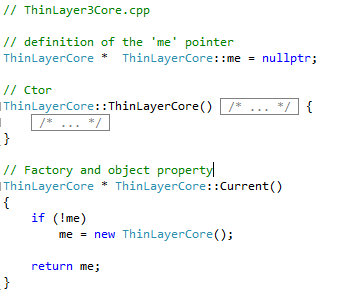
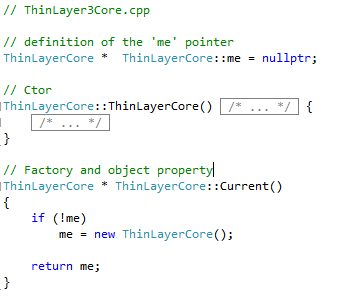
As developed above, the component manages its own lifecycle, but the component does not run on a thread. Below is the singleton class. Just the parts relating to the singleton mechanics are shown. Since the ‘me’ pointer is private, the class’ object dies with the program.

The class implementation, simple as can be.
Asynchronous Method with Callback (IoC with DI)
Consider the following method:

The methods receives three arguments:
– Duration of the session.
– Callback for returning jokes to caller.
– Callback to report progress to caller.
First the method defines a lambda expression f. It is this lambda that does the work. Since every call of this method creates a new lambda object, we don’t need to synchronize access to this code.
The lambda:
– puts the current thread to sleep for a little while.
– Returns a joke (from the seemingly endless collection) using the inserted callback.
– Reports progress by setting a property. Access to this property has to be synchronized, as will be shown below.
– Returns the progress using the inserted callback.
Next the method creates a new thread for the lambda to run on.
Finally the method detaches the thread and returns to the caller. Now the thread runs in the background and is cleaned up by the system after termination. The thread will call on the caller with results, when it has them, using callbacks inserted by the caller. This is how IoC by DI is implemented here.
Now provisions for error handling has been added here. But the lambda could contain a try – catch construct. In addition, we could define a callback output parameter of type std::exception that the callback could throw if not void at return. The lambda can then just send a caught exception to the caller using the callback.
Property with Synchronized Access to Field
The STL contains a *very* elegant mechanism to synchronize access. Consider the following code:

We need only three extra lines of code to completely synchronize access to the m_progress field. One line to declare the mutex, and two lines to lock the field, one time when setting it, one time when reading it.
The great thing of a lock_guard is that it releases its mutex when it goes out of scope. Most elegant!
Events
The same techniques return in our event implementation. Consider the following code:

We have a vector of type newJokeEventHandler, which is a typdef of a std::function object that wraps a pointer to a void function that takes a string argument. Access to the vector is synchronized with a mutex. When an event handler is added, it is added to the end of the vector. When removed, we take care to not disrupt the order in the vector, because the token we returned to the caller is an index into the vector by which we remove it.
An event is raised e.g. in the setter of the ‘JokeOfTheDay’ property:
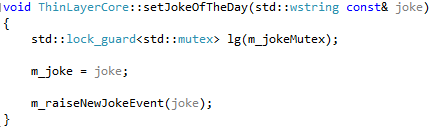
The m_raiseNewJokeEvent returns immediately since it is asynchronous, thus releasing the joke for reading and further updates.
In Conclusion
We have seen that a C++ component that holds its own lifetime and manages its thread can be easily developed. We do not need CX for this, the resulting code is portable. The resulting component is indeed flyweight – because of the elegant constructs provided by the STL for managing threads, and also because the component doesn’t consume any processor cycles when not processing anything. Indeed, applying the sizeof operator to a thread, mutex, or lock_guard yields 4 (x the size of a char) in each case, i.e. they all are minimum size handles to system resources.